

Generating key takeaways...
As AI writing tools become commonplace, concerns grow over the unreliable nature of detection software, which risks mislabeling genuine human work and impacting students, workers, and publishers amid a rapidly evolving AI landscape.
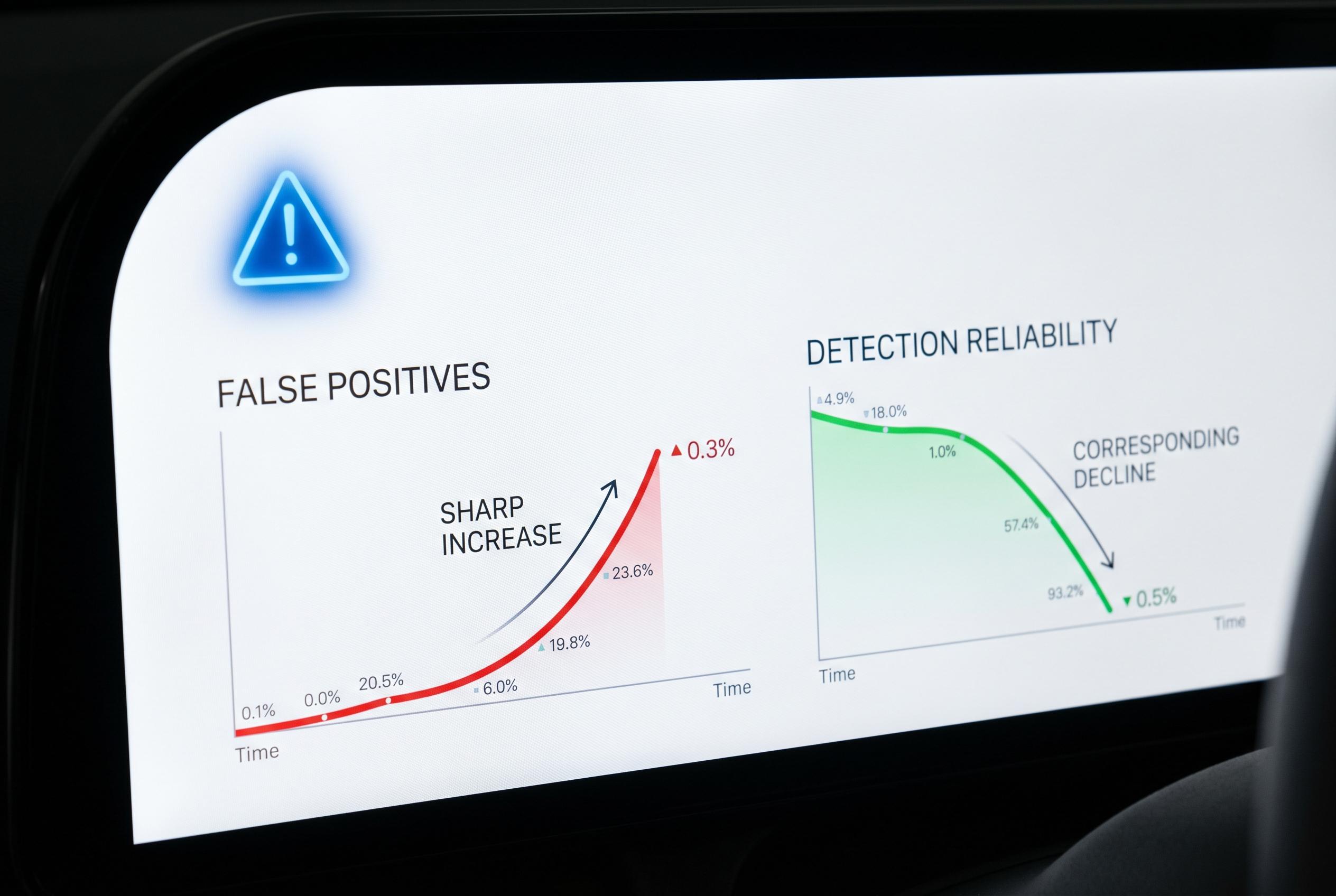
As AI writing tools move from novelty to routine workplace software, the question of who wrote a piece of text has become more fraught. Gallup said in February that half of U.S. employees now use AI in some form at work, a sharp rise that helps explain why schools, publishers and employers are increasingly leaning on detection software to police authenticity. But the tools meant to separate human writing from machine-generated prose can be unreliable, and their mistakes can carry real consequences. According to the original explainer, a false positive occurs when genuine human writing is wrongly labelled as AI-generated, leading to disputed grades, rejected submissions or damaging accusations.
That concern is not abstract. Research cited by AI education and detection specialists suggests that detector performance varies widely and often falls short of the confidence implied by marketing claims. A Stanford study found especially high false-positive rates for some tools when evaluating non-native English writing, while other independent assessments have suggested that the problem is more widespread than some vendors acknowledge. The central issue is that many detectors are built to spot statistical patterns, so ordinary human text can be flagged if it happens to resemble the kind of wording associated with machine output.
The problem is compounded by the pace of change in generative AI itself. As newer models become more fluent, detectors can lag behind, and small adjustments to sensitivity settings can change the result. OpenAI discontinued its own AI Classifier in 2023 after acknowledging weak performance, a sign of how hard the task remains. In education, where the stakes are often high, universities and teachers have been warned against treating detector output as standalone proof of misconduct, especially when writing mixes human drafting, quoted material and paraphrased sections.
That caution is reinforced by recent comparative testing. A University of Chicago study, as reported by TechLearning, found major differences between commercial and open-source systems, with some tools performing well and others producing large error rates. GPTZero, for example, struggled when AI text had been altered to look more human, while other systems were more resilient. The broader lesson is that AI detection may still have a role as one signal among many, but it is not a dependable arbiter on its own, particularly when a false accusation could affect a student’s record, a worker’s reputation or a business’s editorial judgement.
Source Reference Map
Inspired by headline at: [1]
Sources by paragraph:
Source: Noah Wire Services
Noah Fact Check Pro
The draft above was created using the information available at the time the story first
emerged. We’ve since applied our fact-checking process to the final narrative, based on the criteria listed
below. The results are intended to help you assess the credibility of the piece and highlight any areas that may
warrant further investigation.
Freshness check
Score:
8
Notes:
The article was published on March 6, 2026, which is within the past 30 days, indicating high freshness. However, the content references studies and data from 2026, which may not be fully up-to-date. ([humanizedraft.com](https://www.humanizedraft.com/blog/how-accurate-is-gptzero?utm_source=openai))
Quotes check
Score:
7
Notes:
The article includes direct quotes from various sources. While the sources are cited, the exact wording of the quotes cannot be independently verified without accessing the original materials. This lack of direct verification raises concerns about the accuracy of the quotes. ([humanizedraft.com](https://www.humanizedraft.com/blog/how-accurate-is-gptzero?utm_source=openai))
Source reliability
Score:
6
Notes:
The article is published on Zeka Design’s website, which appears to be a design-focused platform. The credibility of this source in the context of AI detection tools is uncertain, as it is not a recognised authority in the field.
Plausibility check
Score:
7
Notes:
The article discusses the challenges of AI detection tools, particularly false positives, which is a known issue in the field. However, the specific claims and statistics presented are not independently verified, raising questions about their accuracy. ([humanizedraft.com](https://www.humanizedraft.com/blog/how-accurate-is-gptzero?utm_source=openai))
Overall assessment
Verdict (FAIL, OPEN, PASS): FAIL
Confidence (LOW, MEDIUM, HIGH): MEDIUM
Summary:
The article presents information on AI detection tools and their challenges, referencing studies and data from 2026. However, the lack of direct access to the original studies, the uncertain credibility of the source, and the inability to independently verify quotes and statistics raise significant concerns about the accuracy and reliability of the content. ([humanizedraft.com](https://www.humanizedraft.com/blog/how-accurate-is-gptzero?utm_source=openai))






