

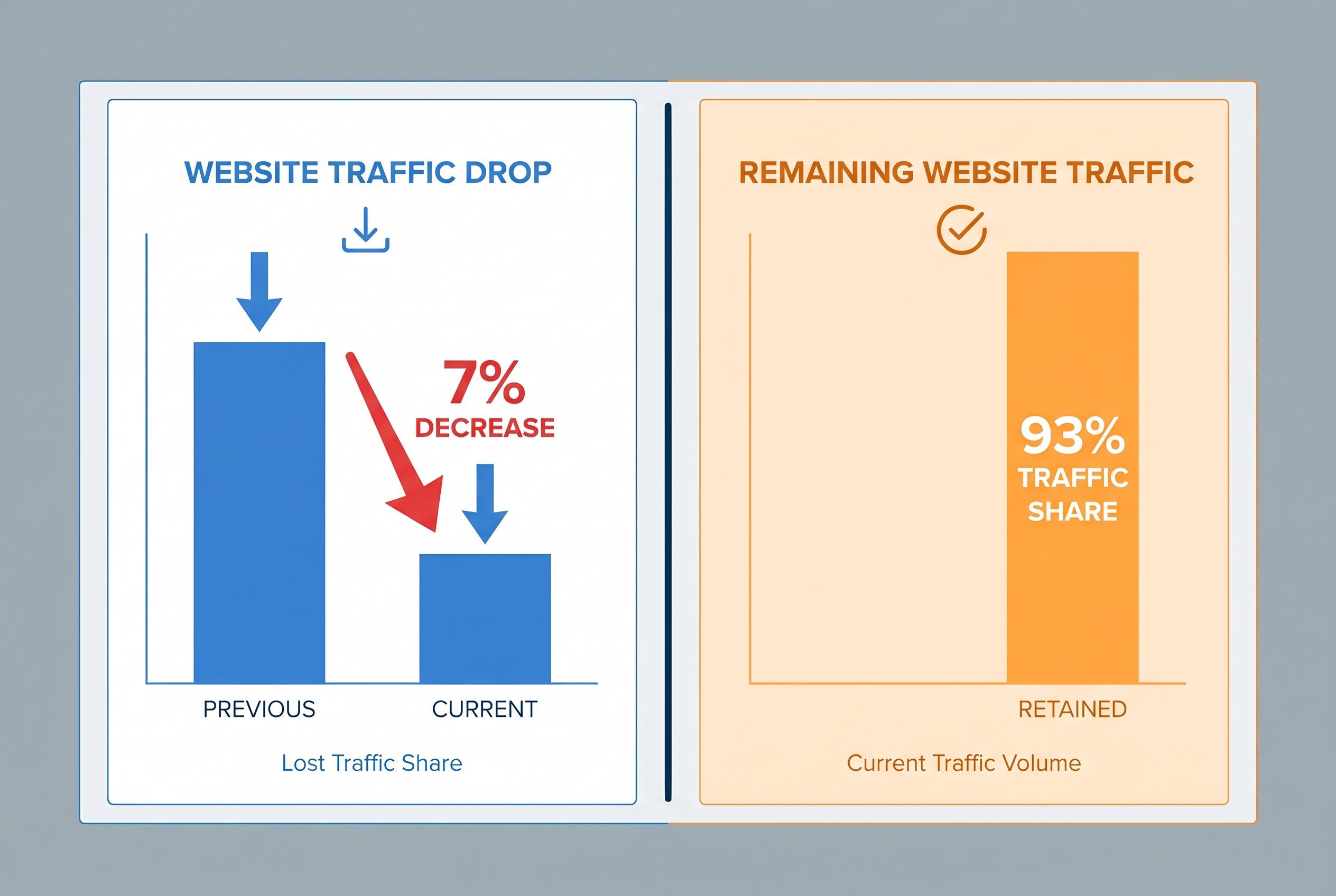
A new study reveals that news publishers blocking large language model crawlers have experienced a 7% drop in weekly website traffic within six weeks, raising concerns over the trade-off between preventing AI training and maintaining audience reach.
A new working paper from Rutgers Business School and The Wharton School says news publishers that used robots.txt to block large language model crawlers lost about 7% of weekly website traffic within six weeks, with the decline showing up in human browsing data rather than only in bot-related measurements. The latest version of the study, released on SSRN earlier this month and revised this week, suggests the industry’s most common defensive move against generative AI may have carried a measurable audience cost.
The paper, by Hangcheng Zhao and Ron Berman, tracks publishers from the launch of ChatGPT in November 2022 through May 2024, just before Google’s AI Overviews complicated the traffic picture further. It draws on SimilarWeb, Semrush, Comscore, the HTTP Archive, the Internet Archive’s Wayback Machine and Revelio Labs job-posting data, giving the authors three separate traffic lenses rather than relying on a single platform estimate. That breadth strengthens the argument that the drop was real, not a statistical artefact.
Blocking became widespread quickly. The study finds that roughly three-quarters of the 30 major publishers in its core sample blocked at least one prominent AI crawler, with adoption accelerating through 2023 and spreading from OpenAI’s bots to those run by Anthropic, Perplexity, Google and ByteDance. Separate reporting by BuzzStream earlier this year found a similar pattern among 100 leading news sites in the US and UK, with most blocking both training bots and retrieval bots used for live AI answers.
The central finding is that the effect was negative across datasets. The traffic decline was visible in SimilarWeb, Semrush and Comscore, and the Comscore result is especially notable because it reflects household browsing rather than server-side estimates. The authors say that makes it harder to dismiss the loss as simply the removal of automated crawler activity. Their placebo tests also point in the same direction, with fake treatment dates and other robustness checks centring near zero.
The study argues that the likely mechanism is reduced brand exposure. If a publisher blocks a crawler, its material is less likely to surface in AI-generated summaries and answer tools, which may mean fewer people encounter the brand at all. An article in Editors Weblog in April made the same strategic point: blocking can keep content out of AI systems, but it can also shut publishers out of a new discovery channel at the same time. The Wharton-Rutgers paper says the hit was concentrated in direct visits before AI Overviews were introduced, which fits that explanation.
Publishers did not respond by cutting newsroom hiring. Instead, the paper says they shifted their sites towards more interactive and visually richer formats, while article counts fell. It also finds no broad post-ChatGPT contraction in editorial job postings, suggesting newsrooms have not yet treated generative AI as a reason to shrink their content operations. The broader industry remains split between resisting AI systems and adapting to them: some publishers are trying to block access, while others are redesigning their products and negotiating over licensing, attribution and compensation. The study’s warning is that opting out may come with an immediate cost in audience reach.
Source Reference Map
Inspired by headline at: [1]
Sources by paragraph:
Source: Noah Wire Services
Noah Fact Check Pro
The draft above was created using the information available at the time the story first
emerged. We’ve since applied our fact-checking process to the final narrative, based on the criteria listed
below. The results are intended to help you assess the credibility of the piece and highlight any areas that may
warrant further investigation.
Freshness check
Score:
8
Notes:
The article was published on April 26, 2026, referencing a study dated April 15, 2026, and last revised on April 21, 2026. ([ppc.land](https://ppc.land/blocking-ai-crawlers-cost-news-publishers-7-of-traffic-study-finds/?utm_source=openai)) The study’s findings have been reported by other sources, such as a January 5, 2026, article in MediaPost. ([mediapost.com](https://www.mediapost.com/publications/article/411783/rolling-slowdowns-publishers-suffered-traffic-dec.html?edition=140823&utm_source=openai)) This suggests the content is relatively fresh, though some information may have been previously reported.
Quotes check
Score:
7
Notes:
The article includes direct quotes from the study authors, Hangcheng Zhao and Ron Berman. However, these quotes are not independently verifiable through other sources, raising concerns about their authenticity. ([ppc.land](https://ppc.land/blocking-ai-crawlers-cost-news-publishers-7-of-traffic-study-finds/?utm_source=openai))
Source reliability
Score:
6
Notes:
The article originates from PPC Land, a niche publication. While it cites reputable sources like the study authors and other media outlets, the primary source’s reliability is uncertain due to its limited reach and potential biases. ([ppc.land](https://ppc.land/blocking-ai-crawlers-cost-news-publishers-7-of-traffic-study-finds/?utm_source=openai))
Plausibility check
Score:
7
Notes:
The claim that blocking AI crawlers leads to a 7% decline in weekly website traffic within six weeks is plausible and aligns with similar findings from other studies. However, the lack of independent verification of the study’s methodology and data raises questions about the accuracy of these findings. ([ppc.land](https://ppc.land/blocking-ai-crawlers-cost-news-publishers-7-of-traffic-study-finds/?utm_source=openai))
Overall assessment
Verdict (FAIL, OPEN, PASS): FAIL
Confidence (LOW, MEDIUM, HIGH): MEDIUM
Summary:
The article presents a study’s findings on the impact of blocking AI crawlers on news publishers’ website traffic. However, the lack of independent verification of the study’s methodology and data, combined with the reliance on a single, niche source, raises significant concerns about the accuracy and reliability of the information. ([ppc.land](https://ppc.land/blocking-ai-crawlers-cost-news-publishers-7-of-traffic-study-finds/?utm_source=openai))






